PubMed API in R#
by Adam M. Nguyen
The recipe examples were tested on Mar 24, 2023.
R easyPubMed Documentation:
Useful Getting Started with easyPubMed Article: https://cran.r-project.org/web/packages/easyPubMed/vignettes/getting_started_with_easyPubMed.html
easyPubMed PDF Documentation: https://cran.r-project.org/web/packages/easyPubMed/easyPubMed.pdf
See the bottom of the document for information on R and package versions.
Setup#
First let’s install the easyPubMed package as well as load the library. If you do not already have the package installed, run the following command in your console: “install.packages(“easyPubMed”, repos = “http://cran.us.r-project.org”)”.
# easyPubMed library for accessing PubMed API
library(easyPubMed)
1. Querying PubMed API#
Below is an example query utilizing some valuable functions provided by the easyPubMed library as well as some important information for the API, if unfamiliar.
These functions include:
get_pubmed_ids()
fetch_pubmed_data()
Note: PubMed employs field tags to specify the nature of the associated string, for a comprehensive list of field tags visit: “https://pubmed.ncbi.nlm.nih.gov/help/#using-search-field-tags”. Additionally, using PubMed tags will limit your search to the specified terms only. While querying PubMed, using the “get_pubmed_ids”, it is allowable to provide no tags and the function will translate it for the user.
Let’s try querying Pubmed! Check comments for additional, step-by-step detail.
example_query <- 'Ancestral population genomics using coalescence hidden Markov models and heuristic optimisation algorithms.[Title]' #State query in the format 'query[query tag]', can include AND and OR statements and a query tag is not required
example_id <- get_pubmed_ids(example_query) #Stores a list of PMIDs(PubMed Identifications) satisfying the query
example_id$IdList$Id
## [1] "25819138"
example_xml <-fetch_pubmed_data(example_id, format = "xml") # Create xml output
Now we have successfully queried and stored the data of ‘Ancestral population genomics using coalescence hidden Markov models and heuristic optimisation algorithms.[Title]’ into the xml output. We will find that working with the xml output is advantageous due to its hierarchical structure.
Next we will show an example of how we can obtain a list of authors from this query using simple R functions and the ‘custom_grep()’ function from easyPubMed.
custom_grep() retrieves data between the tags given
last_name_authors <- custom_grep(example_xml, "LastName", "/LastName") # retrieve last name
forename_authors <- custom_grep(example_xml, "ForeName", "/ForeName") # retrieve forename
example_authors <- rbind('Last Name'=last_name_authors, 'Forename'=forename_authors) # output example_authors dataframe for PMID 27933103
example_authors
## [,1] [,2]
## Last Name "Cheng" "Mailund"
## Forename "Jade Yu" "Thomas"
2. Querying for Multiple Sources#
Another convenience of using easyPubMed is whether requesting data from one article or multiple, it is the same process. The only change that must be made is changing the query, whether that be multiple PMIDs or an Author’s name, as seen in the example below.
multi_example_query <- 'Vincent Scalfani[AU]' # All we need to change here is simply making more general query requests to PubMed.
multi_example_id <- get_pubmed_ids(multi_example_query) #Stores a list of PMIDs satisfying the query
multi_example_xml <-fetch_pubmed_data(multi_example_id, format = "xml") # XML format
# To understand the structure of the XML output, try running the following line without the pound sign, i.e. uncomment
# multi_example_xml
# In the XML format we find Journal Titles to be between "Title" and "/Title"
journals <- custom_grep(multi_example_xml, "Title", "/Title") #Retrieve Journal Titles
Similar to the previous example, now we have retrieved a list of Journal Titles Dr. Scalfani has published under from the articles available on PubMed.
journals
## [1] "Journal of cheminformatics" "Journal of cheminformatics"
## [3] "Science (New York, N.Y.)" "ACS macro letters"
3. Looping Through a List of PMIDs#
In some use cases, a user may be interested in looping through a list of IDs to query data. Below we will show how one can do this.
First, create an example list of PubMed IDs:
pmids = as.list(c(34813985, 34813932, 34813684, 34813661, 34813372, 34813140, 34813072))
Next, let’s begin querying through a for loop. Essentially what is happening is similar to in previous examples, but we are using the for command to iterate over each element of our ‘pmid’ list and then appending the results to our ‘Titles’ list.
# Creates empty list of titles
Titles <- c()
# Iterate through each listed pmid, retrieve XML formatted info, and retrieve list of Titles
for (i in pmids) {
join <- paste(i, '[pmid]') #join each element with [pmid] to specify
id <- get_pubmed_ids(join)
xml <- fetch_pubmed_data(id, format = "xml")
Titles<-append(Titles,custom_grep(xml, "ArticleTitle", "/ArticleTitle"))
Sys.sleep(1)
}
# Display list of titles
Titles
## [1] "Mutation in RyR2-FKBP Binding site alters Ca<sup>2+</sup> signaling modestly but increases \"arrhythmogenesis\" in human stem cells derived cardiomyocytes."
## [2] "M-CDC: Magnetic pull-down-assisted colorimetric method based on the CRISPR/Cas12a system."
## [3] "Naturally occurring UBIAD1 mutations differentially affect menaquinone biosynthesis and vitamin K-dependent carboxylation."
## [4] "Efficient visual screening of CRISPR/Cas9 genome editing in the nematode Pristionchus pacificus."
## [5] "Base Editing of Somatic Cells Using CRISPR-Cas9 in <i>Drosophila</i>."
## [6] "Mammalian Chemical Genomics towards Identifying Targets and Elucidating Modes-of-Action of Bioactive Compounds."
## [7] "CRISPR-Cas9 Editing of the Synthesis of Biodegradable Polyesters Polyhydroxyalkanaotes (PHA) in Pseudomonas putida KT2440."
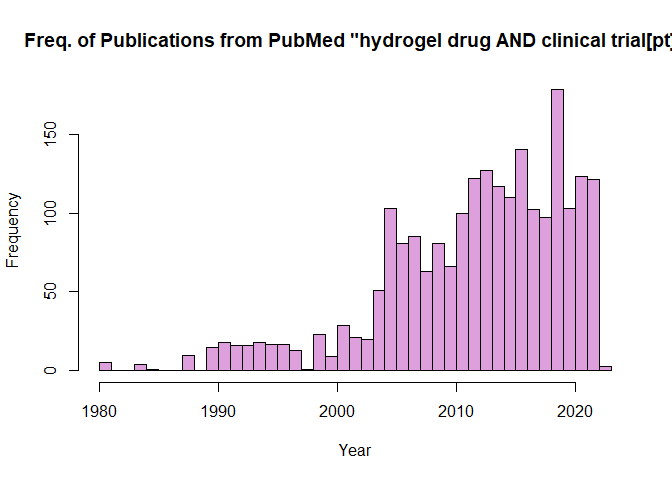
4. PubMed API Metadata Visualization#
In this example we’re going to show how a user can create a visualization using the PubMed API, specifically a histogram to visualize publishing frequency of the query ‘hydrogel drug AND clinical trial[pt]’.
# Libraries for creating network visual
visual_query <- 'hydrogel drug AND clinical trial[pt]' # Example Query
visual_id <- get_pubmed_ids(visual_query) #Stores a list of PMIDs satisfying the query
visual_xml <-fetch_pubmed_data(visual_id, format = "xml") # XML format
Year<- custom_grep(visual_xml, 'Year','/Year') #Retrieve Publication Years
head(Year, n=10) #Display first 10 instances of the Year list
## [1] "2022" "2023" "2022" "2022" "2022" "2022" "2022" "2022" "2022" "2022"
hist(as.numeric(Year),main= 'Freq. of Publications from PubMed "hydrogel drug AND clinical trial[pt]"',xlab='Year', breaks=40, col = 'plum') # Use base R function hist() to plot
R Session Info#
sessionInfo()
## R version 4.2.1 (2022-06-23 ucrt)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 10 x64 (build 19042)
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=English_United States.utf8
## [2] LC_CTYPE=English_United States.utf8
## [3] LC_MONETARY=English_United States.utf8
## [4] LC_NUMERIC=C
## [5] LC_TIME=English_United States.utf8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] easyPubMed_2.13
##
## loaded via a namespace (and not attached):
## [1] digest_0.6.31 R6_2.5.1 jsonlite_1.8.4 evaluate_0.20
## [5] highr_0.10 cachem_1.0.7 rlang_1.0.6 cli_3.6.0
## [9] rstudioapi_0.14 jquerylib_0.1.4 bslib_0.4.2 rmarkdown_2.20
## [13] tools_4.2.1 xfun_0.37 yaml_2.3.7 fastmap_1.1.0
## [17] compiler_4.2.1 htmltools_0.5.4 knitr_1.42 sass_0.4.5